
Online surveys let researchers gauge the thoughts and feelings of their intended demographic (the target market who interact with the product or offerings). Research needs to identify who to include in the survey because not everyone belongs to the target population. First, though, a quick lesson on what sampling actually is, so we can get started with cluster sampling.
What Is Probability Sampling?
One must select a population based on probability theory to undertake a systematic study using probability sampling. In this instance, the researcher selects a representative sample from the population whose attributes they wish to evaluate. As a subset of probability sampling, cluster sampling makes inferences about a population’s characteristics.
It is essential for researchers to determine who to include in the survey study to maximize the quality of insights derived from the data collected. Before conducting polls with online survey software, researchers may use market research tools like SurveyPoint to increase the likelihood of receiving meaningful responses.
Interested in sending your own surveys?
Explore our solutions that help researchers collect accurate insights, boost ROI, and retain respondents using pre-built templates that don’t require coding.
What Is Cluster Sampling?
Cluster sampling is the random selection of a whole group or cluster rather than individual units from a population. The population is initially divided into clusters, often along geographic borders. Then, we randomly choose clusters from all generated clusters to measure all units inside sampled sets. As a result, all people in the sample group have a known and equal chance of being selected.
Very seldom does a researcher employ a two-stage cluster sample design. One first selects a random sample of clusters and then selects a random sample of individuals from inside each cluster. It is also possible to extend the two-stage design into a multi-stage design in which clusters within selected clusters serve as samples. In addition, specialized cluster sampling approaches, such as the World Health Organization’s (WHO) recommended 30 by-7 cluster sample methodology for evaluating immunization programs.
There is a limited amount of sampling within clusters due to their high consistency level. The researchers do not need to collect data on all clusters, which is a benefit of this cluster sample. Only a list of the population’s units is necessary for chosen sets.
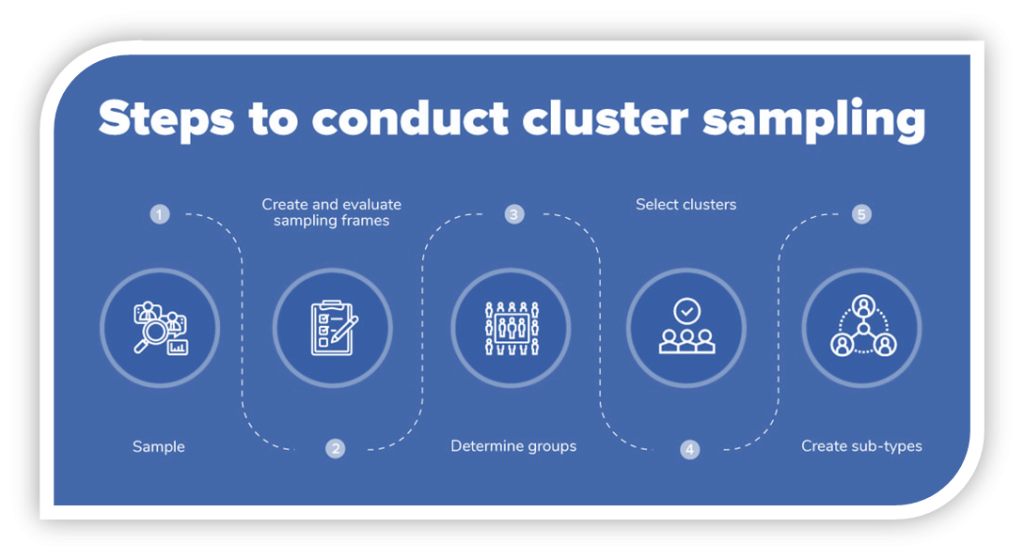
In most cases, cluster sampling is employed with significant changes. For instance, in a public health study, clustering parameters may consist of the population size, health facilities in the area, and the number of vaccinations administered per week, which is proportional to their size. This kind of cluster sample is self-weighted since each unit in the population has an equal chance of being chosen. However, researchers may have a hard time selecting representative samples without knowing the cluster size beforehand.
Instead of selecting clusters based on their size, every cluster will have the same chance of being picked.
Taking the total number of clusters and dividing it by the total number of samples will give the sampling interval (SI). The succeeding units are computed by multiplying the selected random number by the sampling interval. In this specific situation, the sample does not weigh itself. The chance of picking a cluster is not proportional to its size in this circumstance. Hence, this technique alters the odds of picking a certain item to include in the sample.
Advantages of Cluster Sampling
- The simplicity of cluster sampling is its biggest asset. Occasionally, establishing a random sample of the entire population might be difficult. In comparison, selecting clusters and executing measurements on randomly selected sets is far less complicated.
- It allows sampling a group of people for whom it is impossible to collect personal information, i.e., a comprehensive list of individuals within a population does not need to be compiled.
- Cluster sampling leads to substantial time and resource savings, as preparing frames for the whole population is unnecessary. It can decrease travel and other administrative expenditures.
- The result of cluster sampling would not be as precise as that of stratified or random sampling with the same sample size. Nevertheless, due to the substantially lower cost and administrative convenience of cluster sampling, a broader cluster sample may be picked for the equivalent cost estimated for other sampling methods.
- Since cluster lists may be the only easily accessible frames for the target population, cluster sampling may be the only feasible method.
- Cluster sampling simplifies the collection of information on customer preferences in marketing research.
Disadvantages of Cluster Sampling
- The approach often requires a higher total sample size than simple or stratified random sampling.
- Cluster members may be more similar than those in other clusters, which should be kept in mind when calculating sample size and analyzing data.
- The sampling error for a simple random sample of the same size is considerable. The fundamental disadvantage of cluster sampling is its inaccuracy. In spite of the assumption that the preference distributions among the clusters are comparable, this assumption may not be accurate. Therefore, cluster sampling should only be utilized when economically feasible.
- Each cluster should have a similar number of sample units. Thus, cluster sampling may not be suitable for areas with a great deal of diversity in the number of people or families.
- The requirement for more complex calculations compared to simple random sampling is an additional drawback. Moreover, the number of clusters to sample and the size of each duster are difficult to determine.
Kultar Singh – Chief Executive Officer, Sambodhi



